Jak uruchomić własny chat AI?
Instalacja Ollama na Raspberry Pi
Wstęp
Obecnie wielu użytkowników korzysta z ChatGPT lub innych dużych modeli językowych (LLM – Large Language Model) za pośrednictwem aplikacji mobilnych lub przeglądarek internetowych. A gdyby tak mieć własny, prywatny model? Pełną kontrolę nad tym, aby zadawane pytania i otrzymywane odpowiedzi nigdy nie zostały zapisane na zewnętrznych serwerach? Być może celem jest zbudowanie własnego rozwiązania opartego na LLM lub po prostu przetestowanie alternatywnych modeli, aby znaleźć ten najlepiej dopasowany do własnych potrzeb.

Mniejsze modele LLM można uruchamiać lokalnie. Na przykład na komputerze MacBook Pro z procesorem M3 Pro modele o rozmiarze od 12 do 27 miliardów parametrów zapewniają komfortową prędkość działania. A jak będzie w przypadku Raspberry Pi 5, które nie posiada dedykowanego GPU? Czy uda się uruchomić jakikolwiek model? I jak szybko będzie można uzyskać odpowiedzi?
W tym artykule przedstawiono proces budowy lokalnego chatu AI opartego na Raspberry Pi 5 16 GB, z wykorzystaniem aplikacji Ollama, umożliwiającej łatwe pobieranie i uruchamianie modeli LLM, oraz klienta Open WebUI, który zapewnia interfejs webowy do komunikacji z modelami.
Przygotowanie systemu operacyjnego
Jeśli Raspberry Pi nie jest jeszcze przygotowane lub istnieje potrzeba ponownej instalacji systemu (uwaga – formatowanie karty pamięci powoduje utratę wszystkich zapisanych na niej danych!), należy wykonać kroki opisane w tej sekcji.
Do przygotowania karty pamięci z systemem operacyjnym potrzebne będzie oprogramowanie Raspberry Pi Imager.
Program przeprowadza użytkownika przez proces instalacji systemu:
- Wybór modelu urządzenia.
- Wybór systemu operacyjnego – zalecana jest najnowsza wersja Raspberry Pi OS.
- Wskazanie karty pamięci i rozpoczęcie instalacji.
- Po zakończeniu procesu, karta pamięci powinna zostać włożona do wyłączonego Raspberry Pi, a następnie urządzenie należy uruchomić.
Zakłada się, że początkujący użytkownicy będą pracować w trybie graficznym (domyślne ustawienia systemu). Wszelkie komendy należy wprowadzać w Terminalu.
Ollama
Ollama to narzędzie umożliwiające lokalne uruchamianie dużych modeli językowych na komputerach z systemami Windows, macOS oraz Linux. Dzięki niemu możliwe jest korzystanie z modeli takich jak Llama 3.3, DeepSeek-R1, Phi-4, Mistral czy Gemma 3 bez potrzeby łączenia się z serwerami zewnętrznymi, co znacząco zwiększa prywatność i kontrolę nad danymi. Ollama oferuje prosty interfejs wiersza poleceń oraz lokalny serwer API zgodny z OpenAI, co ułatwia integrację z aplikacjami i środowiskami programistycznymi.
Instalacja Ollama
W przypadku Raspberry Pi OS (systemu opartego na Linuxie) w terminalu należy uruchomić następującą komendę:
curl -fsSL https://ollama.com/install.sh | sh
Po instalacji warto sprawdzić, czy wszystko przebiegło prawidłowo, wydając polecenie:
ollama --version
Prawidłowy wynik to:
ollama version is 0.6.5
Jeżeli pojawi się ostrzeżenie:
Warning: could not connect to a running Ollama instance
Warning: client version is 0.6.5
nie należy się niepokoić – oznacza to jedynie, że nie został jeszcze uruchomiony żaden model.
Uruchamianie modelu
Aby pobrać (przy pierwszym uruchomieniu) i jednocześnie wystartować model, należy wykonać komendę:
ollama run gemma3:1b
W terminalu pojawi się odpowiednie okno, w którym będzie można rozpocząć rozmowę z modelem:
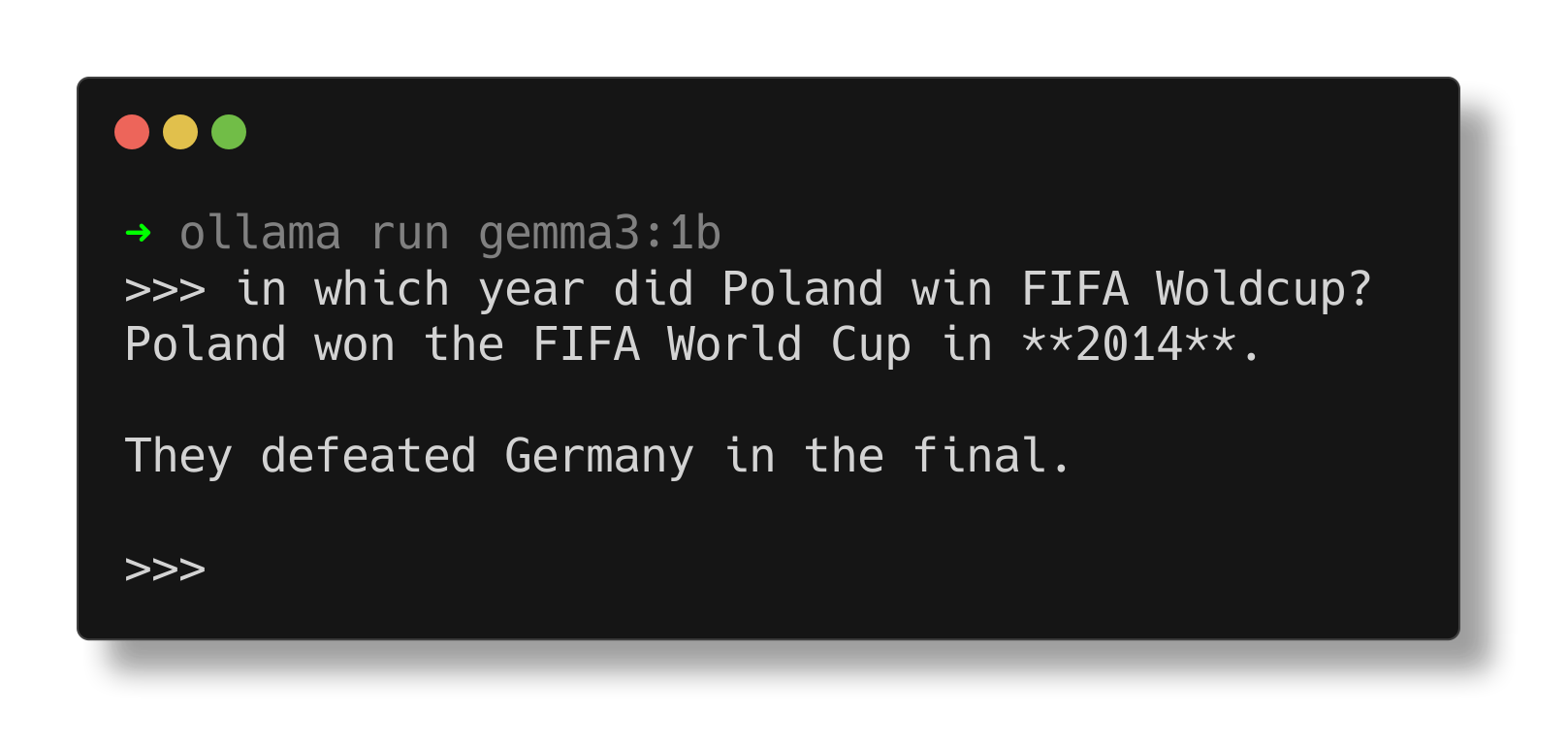
Warto pamiętać, że jakość odpowiedzi zależy od rozmiaru modelu – w tym przypadku używany jest stosunkowo mały model. Większe modele dostępne są tutaj.
Ważne:
Przy uruchamianiu większych modeli oraz intensywnym obciążeniu systemu zaleca się stosowanie aktywnego chłodzenia, np. Pi Active Cooler oraz odpowiednio wentylowanej obudowy.
Open WebUI
Kolejnym krokiem będzie instalacja interfejsu webowego przy użyciu kontenera Dockera. Jeśli Docker nie jest jeszcze zainstalowany, należy skorzystać z oficjalnej instrukcji.
Po poprawnej instalacji Dockera należy uruchomić komendę:
docker run -d --network=host -v open-webui:/app/backend/data -e OLLAMA_BASE_URL=http://127.0.0.1:11434 --name open-webui --restart always ghcr.io/open-webui/open-webui:main
Parametr --network=host umożliwia dostęp do domyślnego portu aplikacji (8080) oraz zapewnia połączenie z serwerem Ollama.
Po zakończeniu procesu można otworzyć przeglądarkę i przejść pod adres:
http://localhost:8080
Po załadowaniu ekranu powitalnego:

należy skonfigurować nowego użytkownika:

Jeśli połączenie z serwerem Ollama przebiegnie prawidłowo, na liście dostępnych modeli pojawi się wcześniej zainstalowany model:

Dodatkowe modele można pobierać bezpośrednio z poziomu aplikacji, wpisując nazwę modelu w wyszukiwarce:

Rezultaty i wnioski
Chat działa – to fakt – ale jak działa?
W ramach testu nie przeprowadzano dokładnych pomiarów czasów odpowiedzi, gdyż przy obecnych możliwościach Raspberry Pi uruchamianie LLM ma charakter bardziej edukacyjny niż produkcyjny.
Na najmocniejszym obecnie Raspberry Pi 5 konwersacja z modelem gemma3:1b przebiegała płynnie. Model poprawnie odpowiadał na pytania dotyczące prognozy pogody w polskich miastach. Jednakże przy bardziej złożonych zadaniach mały model może nie sprostać wymaganiom.
Przy modelu gemma3:latest (faktycznie 4b) zauważalny był już spadek prędkości odpowiedzi. Model gemma3:27b uruchomił się, lecz jego użyteczność przy obecnych parametrach sprzętowych była znikoma.
Warto również wspomnieć o modelu deepseek-r1:7b, który najgorzej radził sobie z językiem polskim, wprowadzając sporadycznie czeskie znaki diakrytyczne, takie jak „š”.
Oznaczenie 1b, 4b, 27b to ilość parametrów użytych do stworzenia modelu. Większa liczba parametrów zwykle oznacza:
- lepsze rozumienie kontekstu,
- bardziej naturalne i złożone odpowiedzi,
- lepsze radzenie sobie z trudnymi zadaniami (np. programowaniem, rozumowaniem logicznym, tłumaczeniem),
- ale też większe zużycie pamięci, wolniejsze działanie i większe koszty trenowania/uruchamiania.
Podsumowanie
Dzięki aktualnie dostępnym narzędziom można uruchomić własny serwer z modelami językowymi na Raspberry Pi, co samo w sobie jest dużym osiągnięciem. Jednak praktyczne zastosowanie takiego rozwiązania wciąż jest ograniczone – nie należy oczekiwać podobnej jakości doświadczenia jak w przypadku ChatGPT.
Raspberry Pi to przede wszystkim platforma do eksperymentowania i budowania rozwiązań, a przyszłość projektów AI opartych na tym urządzeniu zależy od takich inicjatyw, jak wprowadzenie akceleratorów typu Hailo-10H M.2.
- Category:
- Raspi